9.6 Minimal Cost Spanning Trees
The minimal-cost spanning tree (MCST) problem takes as input a connected, undirected graph , where each edge has a distance or weight measure attached. The MCST is also called minimum spanning tree (MST).
The MCST is the graph containing the vertices of along with the subset of ’s edges that (1) has minimum total cost as measured by summing the values for all of the edges in the subset, and (2) keeps the vertices connected. Applications where a solution to this problem is useful include soldering the shortest set of wires needed to connect a set of terminals on a circuit board, and connecting a set of cities by telephone lines in such a way as to require the least amount of cable.
The MCST contains no cycles. If a proposed MCST did have a cycle, a cheaper MCST could be had by removing any one of the edges in the cycle. Thus, the MCST is a free tree with edges. The name “minimum-cost spanning tree” comes from the fact that the required set of edges forms a tree, it spans the vertices (i.e., it connects them together), and it has minimum cost. Figure #MCSTdgm shows the MCST for an example graph.
A graph and its MCST. All edges appear in the original graph. Those edges drawn with heavy lines indicate the subset making up the MCST. Note that edge could be replaced with edge to form a different MCST with equal cost.
9.6.1 Prim’s Algorithm
The first of our two algorithms for finding MCSTs is commonly referred to as Prim’s algorithm. Prim’s algorithm is very simple. Start with any Vertex in the graph, setting the MCST to be initially. Pick the least-cost edge connected to . This edge connects to another vertex; call this . Add Vertex and Edge to the MCST. Next, pick the least-cost edge coming from either or to any other vertex in the graph. Add this edge and the new vertex it reaches to the MCST. This process continues, at each step expanding the MCST by selecting the least-cost edge from a vertex currently in the MCST to a vertex not currently in the MCST.
Prim’s algorithm is quite similar to Dijkstra’s algorithm for finding the single-source shortest paths. The primary difference is that we are seeking not the next closest vertex to the start vertex, but rather the next closest vertex to any vertex currently in the MCST. Thus the following lines in Djikstra’s algorithm:
dist = D.get(v) + e.weight
if dist < D.get(w):
D.put(w, dist)are replaced with the following lines in Prim’s algorithm:
if e.weight < D.get(w):
D.put(w, e.weight)The following code shows an implementation for Prim’s algorithm that searches the distance matrix for the next closest vertex.
// Compute shortest distances to the MCST, store them in D.
// parent.get(v) will hold the index for the vertex that is v's parent in the MCST
function Prim(G, s):
visited = new Set()
parent = new Map()
D = new Map()
for each v in G.vertices():
D.put(v, ∞)
D.put(s, 0)
repeat G.vertxCount() times: // Process the vertices
v = minVertex(G, D, visited) // Find next-closest vertex
visited.add(v)
if D.get(v) == ∞:
return parent
for each e in G.outgoingEdges(v):
w = e.end
if e.weight < D.get(w):
D.put(w, e.weight)
parent.put(w, v)
return parentFor each vertex e, when e is processed by Prim’s
algorithm, an edge going to e is added to the MCST that we are
building. Array V[e] stores the previously visited vertex
that is closest to Vertex e. This information lets us know
which edge goes into the MCST when Vertex e is processed.
9.6.2 Prim’s Algorithm, Priority Queue Implementation
Alternatively, we can implement Prim’s algorithm using a priority
queue to find the next closest vertex, as shown next. As with the
priority queue version of Dijkstra’s algorithm, the heap
stores DijkElem objects.
// Prim's MCST algorithm: priority queue version
function PrimPQ(G, s):
visited = new Set()
parent = new Map()
D = new Map()
for (v : G.vertices())
D.put(v, ∞)
D.put(s, 0)
agenda = new PriorityQueue()
agenda.add(new KVPair(0, s))
while not agenda.isEmpty():
v = agenda.removeMin().value
if v not in visited:
visited.add(v)
if D.get(v) == ∞:
return parent
for each e in G.outgoingEdges():
w = e.end
if e.weight < D.get(w):
D.put(w, e.weight)
parent.put(w, v)
agenda.add(new KVPair(e.weight, w))
return parentPrim’s algorithm is an example of a greedy algorithm. At each step in
the for loop, we select the least-cost edge that connects
some marked vertex to some unmarked vertex. The algorithm does not
otherwise check that the MCST really should include this least-cost
edge. This leads to an important question: Does Prim’s algorithm work
correctly? Clearly it generates a spanning tree (because each pass
through the for loop adds one edge and one unmarked vertex
to the spanning tree until all vertices have been added), but does this
tree have minimum cost?
Theorem: Prim’s algorithm produces a minimum-cost spanning tree.
Proof: We will use a proof by contradiction. Let be a graph for which Prim’s algorithm does not generate an MCST. Define an ordering on the vertices according to the order in which they were added by Prim’s algorithm to the MCST: . Let edge connect for some and . Let be the lowest numbered (first) edge added by Prim’s algorithm such that the set of edges selected so far cannot be extended to form an MCST for . In other words, is the first edge where Prim’s algorithm “went wrong.” Let be the “true” MCST. Call the vertex connected by edge , that is, .
Because is a tree, there exists some path in connecting and . There must be some edge in this path connecting vertices and , with and . Because is not part of , adding edge to forms a cycle. Edge must be of lower cost than edge , because Prim’s algorithm did not generate an MCST. This situation is illustrated in Figure #PrimProof. However, Prim’s algorithm would have selected the least-cost edge available. It would have selected , not . Thus, it is a contradiction that Prim’s algorithm would have selected the wrong edge, and thus, Prim’s algorithm must be correct.
Figure: Proof of Prim’s algorithm
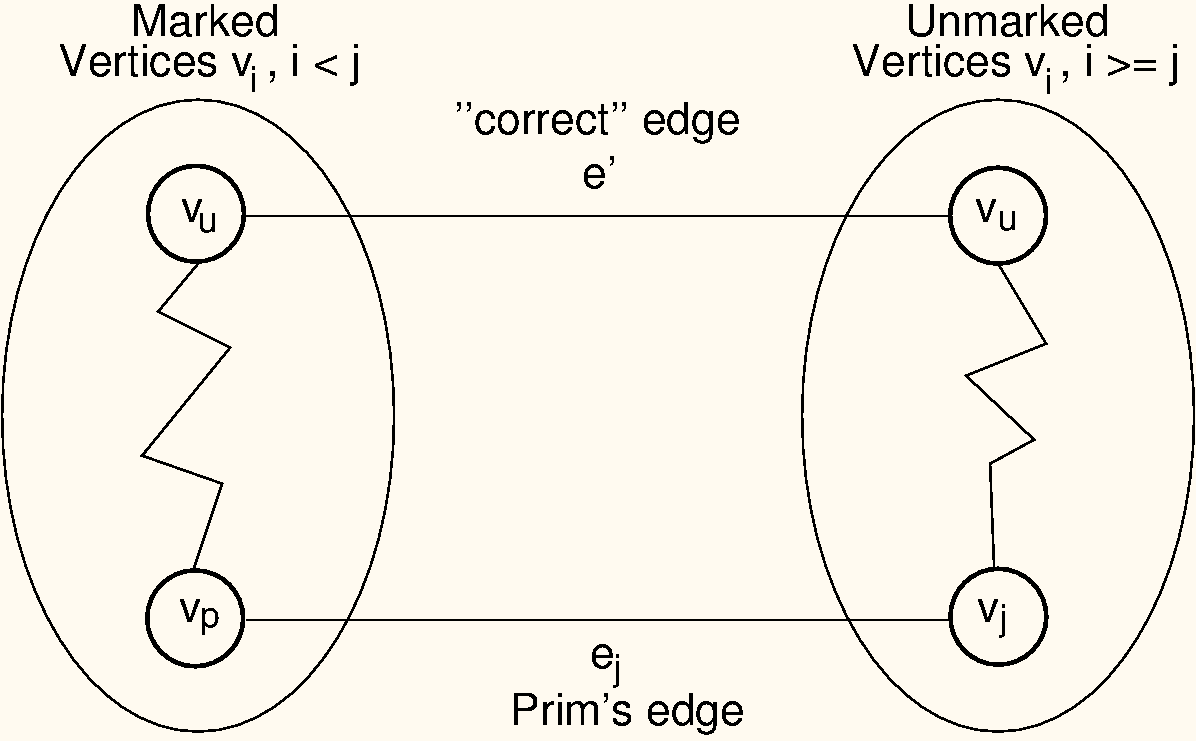
Prim’s MCST algorithm proof. The left oval contains that portion of the graph where Prim’s MCST and the “true” MCST agree. The right oval contains the rest of the graph. The two portions of the graph are connected by (at least) edges (selected by Prim’s algorithm to be in the MCST) and (the “correct” edge to be placed in the MCST). Note that the path from to cannot include any marked vertex , because to do so would form a cycle.
9.6.3 Kruskal’s Algorithm
Our next MCST algorithm is commonly referred to as Kruskal’s algorithm. Kruskal’s algorithm is also a simple, greedy algorithm. First partition the set of vertices into disjoint sets, each consisting of one vertex. Then process the edges in order of weight. An edge is added to the MCST, and two disjoint sets combined, if the edge connects two vertices in different disjoint sets. This process is repeated until only one disjoint set remains.
The edges can be processed in order of weight by putting them in an array and then sorting the array. Another possibility is to use a minimum priority queue, similar to what we did in Prim’s algorithm.
The only tricky part to this algorithm is determining if two vertices belong to the same equivalence class. Fortunately, the ideal algorithm is available for the purpose – the UNION/FIND algorithm. Here is an implementation for Kruskal’s algorithm. Note that since the MCST will never have more than edges, we can return as soon as the MCST contains enough edges.
// Kruskal's MCST algorithm
function Kruskal(G):
A = new ParentPointerTree()
for each v in G.vertices():
A.MAKE_SET(v) // Create one singleton set for each vertex
edges = new PriorityQueue()
for each v in G.vertices():
for each e in G.outgoingEdges(v):
edges.add(new KVPair(e.weight, e))
numEdgesInMCST = 0
while not edges.isEmpty():
e = edges.removeMin()
if A.FIND(e.start) != A.FIND(e.end): // If the vertices are not connected...
AddEdgetoMCST(edge) // ...add this edge to the MCST
numEdgesInMCST = numEdgesInMCST + 1
if numEdgesInMCST >= G.vertexCount()-1:
return A // Stop when the MCST has |V|-1 edges
A.UNION(e.start, e.end) // Connect the two verticesKruskal’s algorithm is dominated by the time required to process the
edges. The FIND and UNION functions are nearly
constant in time if path compression and weighted union is used. Thus,
the total cost of the algorithm is
in the worst case, when nearly all edges must be processed before all
the edges of the spanning tree are found and the algorithm can stop.
More often the edges of the spanning tree are the shorter ones, and only
about
edges must be processed. If so, the cost is often close to
in the average case (provided we use a priority queue instead of sorting
all edges in advance).