13.6 Prim’s algorithm for finding the MST
The first of our two algorithms for finding MSTs is commonly referred to as Prim’s algorithm. Prim’s algorithm is very simple. Start with any vertex in the graph, setting the MST to be initially. Pick the least-cost edge connected to . This edge connects to another vertex; call this . Add vertex and edge to the MST. Next, pick the least-cost edge coming from either or to any other vertex in the graph. Add this edge and the new vertex it reaches to the MST. This process continues, at each step expanding the MST by selecting the least-cost edge from a vertex currently in the MST to a vertex not currently in the MST.
The following code shows an implementation for Prim’s algorithm that searches the distance matrix for the next closest vertex.
function prim(graph, start):
visited = new Set() of vertices
parent = new Map() of vertices to vertices
distances = new Map() of vertices to their distance from the MST
// The distance from start to the MST is 0:
distances.put(start, 0)
repeat graph.size times:
v = minVertex(graph, distances, visited) // Find next-closest vertex
visited.add(v)
for each e in graph.outgoingEdges(v):
if e.end not in distances or e.weight < distances.get(e.end):
// If the edge makes the endpoint closer to the MST,
// update the endpoint with the new distance, and add it to the MST
distances.put(e.end, e.weight)
parent.put(e.end, v)
return parentFor each vertex v, when v is processed by Prim’s
algorithm, an edge going to v is added to the MST that we are
building. The parent map stores the previously visited
vertex that is closest to vertex v. This information lets us
know which edge goes into the MST when vertex v is
processed.
Here is a visualisation of Prim’s algorithm.
Finding the minimum vertex
There are two reasonable solutions to the key issue of finding the
unvisited vertex with minimum distance value during each pass through
the main for loop. The first method is simply to scan
through the list of
vertices searching for the minimum value, as follows:
function minVertex(graph, distances, visited):
minV = null
for each v in graph.vertices():
if v not in visited:
if minV is null or distances.get(v) < distances.get(minV):
minV = v
return minVBecause this scan is done times, and because each edge requires a constant-time update to , the total cost for this approach is , because is in .
13.6.1 Priority queue implementation of Prim’s algorithm
An alternative approach is to store unprocessed vertices in a minimum priority queue, such as a binary heap, ordered by their distance from the processed vertices. The next-closest vertex can be found in the heap in time. Every time we modify , we could reorder in the heap by deleting and reinserting it. This is an example of a priority queue with priority update. However, to implement true priority updating, we would need to store with each vertex its position within the heap so that we can remove its old distances whenever it is updated by processing new edges.
A simpler approach is to add the new (always smaller) distance value for a given vertex as a new record in the heap. The smallest value for a given vertex currently in the heap will be found first, and greater distance values found later will be ignored because the vertex will already be marked as visited. The only disadvantage to repeatedly inserting distance values in this way is that it will raise the number of elements in the heap from to in the worst case. But in practice this only adds a slight increase to the depth of the heap. The time complexity is , because for each edge that we process we must reorder the heap.
Here is the implementation for Dijkstra’s algorithm using a priority queue.
function primPQ(graph, start):
visited = new Set() of vertices
parent = new Map() of vertices to vertices
distances = new Map() of vertices to their distance from the MST
agenda = new PriorityQueue() of vertices ordered by their distance from the MST
// The distance from start to start is 0:
distances.put(start, 0)
agenda.add(start) with priority 0
while not agenda.isEmpty():
v = agenda.removeMin()
if v not in visited:
visited.add(v)
for each e in graph.outgoingEdges():
if e.end not in distances or dist < distances.get(e.end):
// If the edge makes the endpoint closer to the MST,
// update the endpoint with the new distance,
// add it to the MST and the agenda
distances.put(e.end, e.weight)
parent.put(e.end, v)
agenda.add(e.end) with priority e.weight
return parent13.6.2 Correctness of Prim’s algorithm
Prim’s algorithm is an example of a greedy algorithm. At each step in
the for loop, we select the least-cost edge that connects
some marked vertex to some unmarked vertex. The algorithm does not
otherwise check that the MST really should include this least-cost edge.
This leads to an important question: Does Prim’s algorithm work
correctly? Clearly it generates a spanning tree (because each pass
through the for loop adds one edge and one unmarked vertex
to the spanning tree until all vertices have been added), but does this
tree have minimum cost?
Theorem: Prim’s algorithm produces a minimum-cost spanning tree.
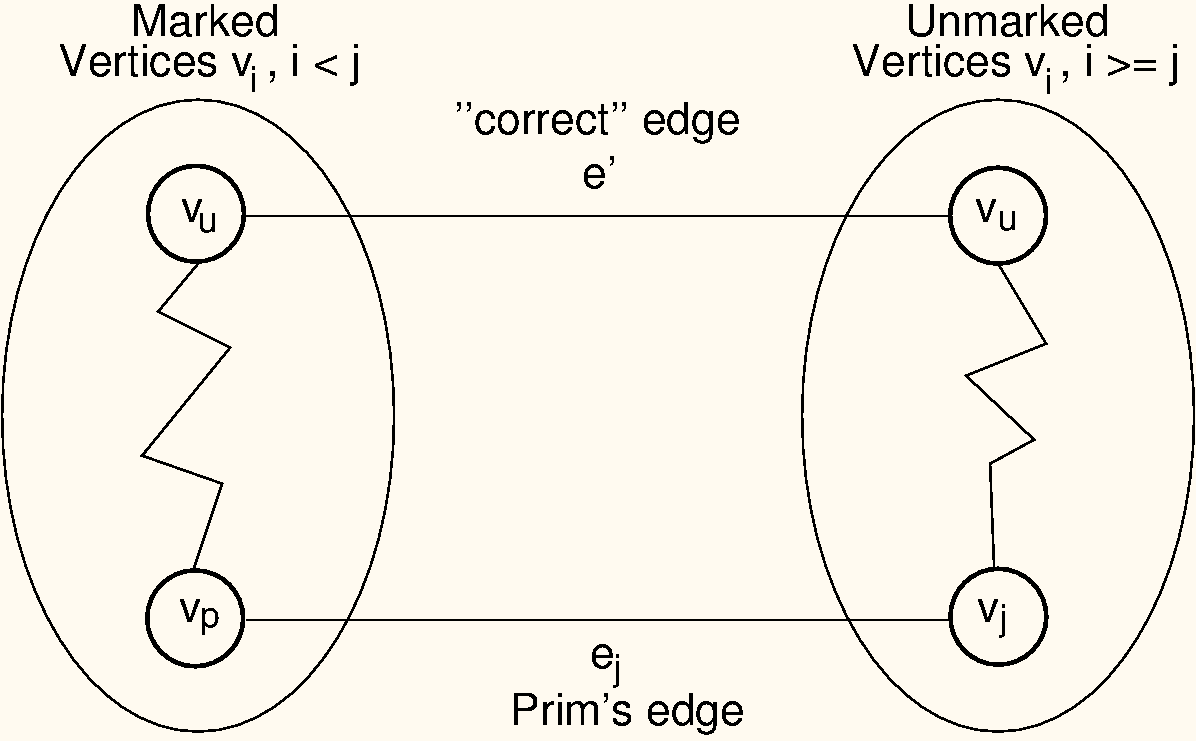
Proof: We will use a proof by contradiction. Let be a graph for which Prim’s algorithm does not generate an MST. Define an ordering on the vertices according to the order in which they were added by Prim’s algorithm to the MST: . Let edge connect for some and . Let be the lowest numbered (first) edge added by Prim’s algorithm such that the set of edges selected so far cannot be extended to form an MST for . In other words, is the first edge where Prim’s algorithm “went wrong.” Let be the “true” MST. Call the vertex connected by edge , that is, . Because is a tree, there exists some path in connecting and . There must be some edge in this path connecting vertices and , with and . Because is not part of , adding edge to forms a cycle. Edge must be of lower cost than edge , because Prim’s algorithm did not generate an MST. This situation is illustrated in Figure 13.11. However, Prim’s algorithm would have selected the least-cost edge available. It would have selected , not . Thus, it is a contradiction that Prim’s algorithm would have selected the wrong edge, and thus, Prim’s algorithm must be correct.